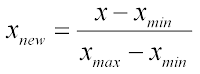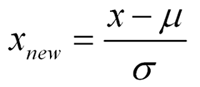수정주가
기업에 증자, 액면분할 등 이벤트가 발생하면 주식수와 함께 주가에 변화가 생긴다.
이때 현재 주가의 수준을 과거와 비교 가능하게 하기위해 과거 주가도 함께 수정하는데, 이것이 수정주가.
예를들어 1주에 1000원짜리 10주가 발행되어 시가총액인 10,000원이었는데,
무상증자가 되어 10주에서 100주가 되었다고 하자.
그러면 시가총액을 10,000원으로 동일하게 맞추려면 주가가 100원으로 떨어져야
100원 x 100주 = 10,000원이 된다.
근데 이럴 경우, 주가만 보면 1,000원에서 100원으로 1/10 감소하는데, 일별수익률을 계산하면 큰폭으로 하락한걸로 계산되지만 실제로는 증자만 되었을뿐, 기업의 가치인 시가총액은 변함이 없다.
따라서 이경우 변경후인 100원을 수정주가라 하고, 이전 주가도 현재주가인 100원 기준으로 다 변경해주고 나면 일별수익률을 계산했을때 1.0으로 변동이 없게 된다.
한가지 의문은 수정주가 작업을 통해서 과거 주가는 변경을 해주었는데, 과거 거래량을 같이 변경해주지 않으면, 거래금액(=거래량 x 거래가격)에 오차가 발생하지 않겠느냐 하는 부분.
배당금
개인의 수익률 관점 : 올라간다.
현금배당이 있는 경우 실질수익률이 주가만 따졌을 경우의 수익률 보다 크다.
예를 들어 삼성전자 보통주를 2000년 1월 2일에 투자해 2010년 11월 말까지 그대로 보유한 경우 주가만으로는 214.3%의 수익률을 나타내지만 현금배당을 포함한 실질적인 수익률은 260.1%에 달한다. 단순 주가만을 반영한 수익률보다 45.8%포인트나 높은 셈이다.
주식 자체의 수익률 관점 : 떨어진다.
배당일이 지나면 반드시 주가가 떨어지는데, 위에서 무상증자로 인한 주가 감소와 유사하다.
이경우 수정주가를 적용하지 않으면 주식 자체의 일별수익률 역시 감소한다.
따라서 배당에 대한 수정주가를 지원하는 HTS등의 경우 배당전의 주가를 배당후의 주가 기준으로 일괄변경하는 수정주가가 적용되고,
이럴경우 수정주가 적용후 일별 수익률은 1.0으로 맞춰진다.
'재무 금융' 카테고리의 다른 글
| 마이데이터 관점에서 본 OAuth2.0 (0) | 2020.09.23 |
|---|---|
| 공인인증서와 전자서명 (0) | 2020.07.30 |
| CAPM(Capital Asset Pricing Model, 자본자산가격결정모형) (0) | 2019.01.17 |
| Risk Parity 전략 (0) | 2018.01.30 |
| 위험조정수익률(risk-adjusted return) (0) | 2018.01.26 |









![{\displaystyle {\begin{alignedat}{1}R_{x}(\theta )&={\begin{bmatrix}1&0&0\\0&\cos \theta &-\sin \theta \\[3pt]0&\sin \theta &\cos \theta \\[3pt]\end{bmatrix}}\\[6pt]R_{y}(\theta )&={\begin{bmatrix}\cos \theta &0&\sin \theta \\[3pt]0&1&0\\[3pt]-\sin \theta &0&\cos \theta \\\end{bmatrix}}\\[6pt]R_{z}(\theta )&={\begin{bmatrix}\cos \theta &-\sin \theta &0\\[3pt]\sin \theta &\cos \theta &0\\[3pt]0&0&1\\\end{bmatrix}}\end{alignedat}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a6821937d5031de282a190f75312353c970aa2df)