
Normalization
Normalization은 모든 실수 데이터들 [0,1] range로 변환하는 걸 의미한다.
예를 들면 다음과 같다.
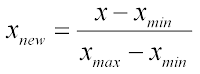
Standardization(=z-transform)
Standardization은 반면 평균을 0으로 만들고 unit variance를 같도록 표준편차로 나누는 작업을 의미한다(z-score)
(결국 평균은0이고 표준편차는 1이되도록 바뀐다)
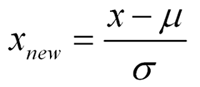
Normalization의 단점은 outlier가 있어서 매우 크게 튀는 값이 있으면 모든 값을 [0,1]사이에 넣는 속성 때문에 다른 정상(?)값들이 작은 범위에 들어가게 된다는 점이다.
Standardization의 경우는 Normalization과 다르게 [0,1]등 특정 범위에 bound되지는 않는다.
따라서 대부분의 경우는 Normalization보다 Standardization이 좀 더 추천됨
표준편차로 나누는 대신 IQR을 사용하는 방법도 있다. 여기 참조
표준편차는 +-시그마 범위가 68.27%라서 이를 50%로 사용하고 자 할 때 사용(전체 데이터를 4등분해서 outlier여부를 체크하는 등)
또는 10등분해서 상하위 10%를 outlier로 체크하는 방법도 가능(outlier면 범위안으로 값을 바꾼다던지 = clipping = clamping또는 Winsorizing)
Log transformation
값들이 10배수 이상씩 차이가 크다면 log를 씌워서 간격을 줄일 수 있다.
하지만 log는 양수에만 씌울 수 있어서 값에 0이나 음수가 있다면 좀 더 고민이 필요하다.(아래 그래프 참조)

반응형
'AI, ML > ML' 카테고리의 다른 글
| 의사결정나무(Decision Tree) (0) | 2019.02.07 |
|---|---|
| [데이터 전처리] clipping vs trimming (1) | 2019.01.04 |
| Gym (0) | 2018.11.07 |
| 크로스엔트로피 손실함수 (0) | 2018.10.02 |
| credit assignment problem (0) | 2018.09.27 |