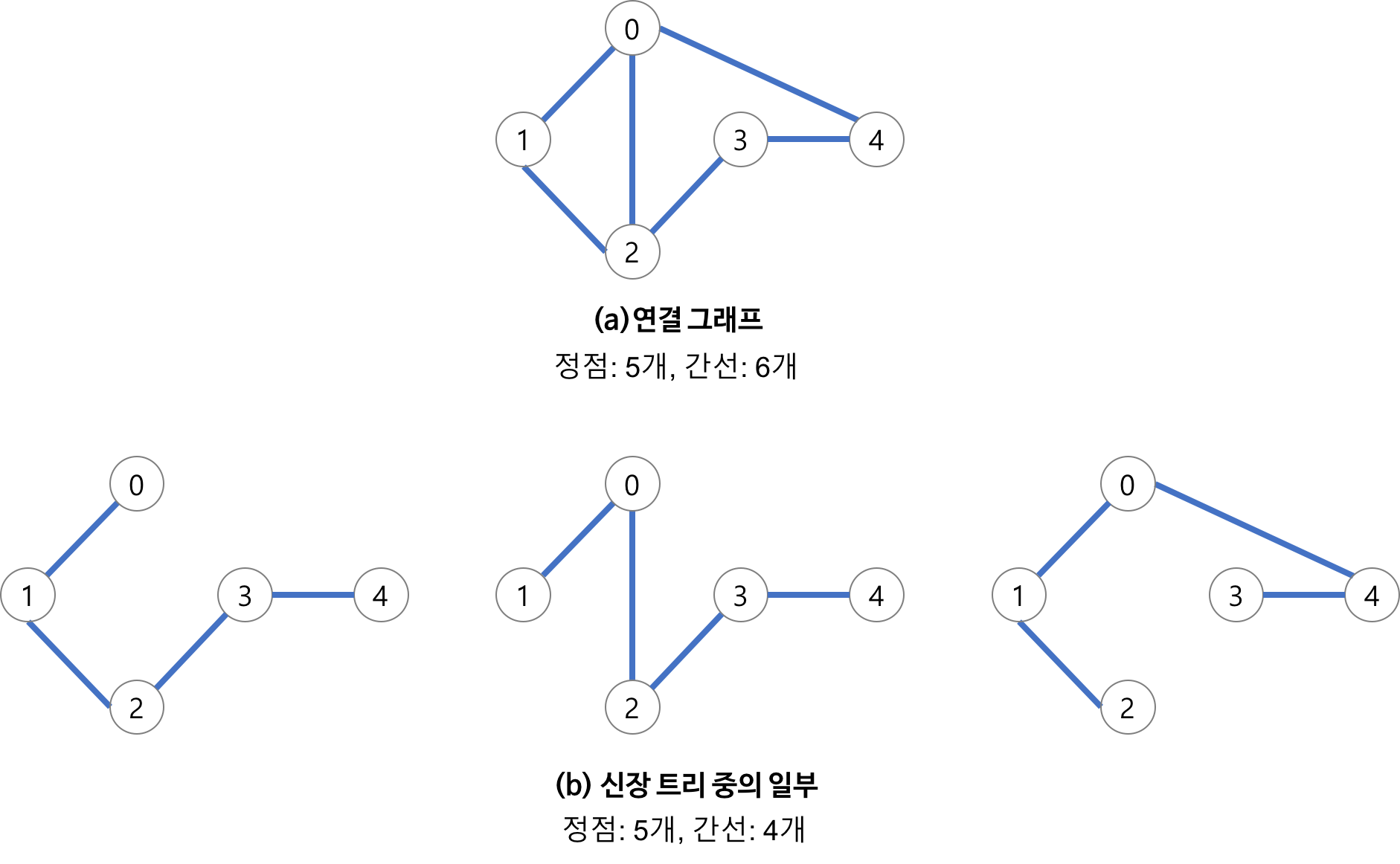
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
using vvi = vector<vi>;
const int INF = (int)1e9;
//무방향그래프를 인풋으로 받아, 트리로 만들어준다.LCA를 위한 작업도 해준다.
struct result {vvi tree;int root;vi parent,level; int max_level;vvi ancestor;};
result treefy(vector<vi>& adj_list, int root = -1, bool base1 = false) {
int max_v = (int)adj_list.size();
vector<vi> tree(max_v);
if (root == -1)
{
// find root(왼쪽이 parent인경우만 성립하는듯, 안그러면 root가 여러개다)
map<int, int> m;
for (int i = (int)base1; i < max_v; i++)
for (auto a : adj_list[i]) m[a]++;
for (int i = (int)base1; i < max_v; i++)
if (m[i] == 0) { root = i; break; }
}
vi parent(max_v), level(max_v);
int max_level = (int)floor(log2(max_v));
// ac[y][x] :: x의 2^y번째 조상을 의미
vvi ac(max_level + 1, vi(max_v, -INF));
function<void(int, int, int)> dfs = [&](int node, int par, int lv) {
parent[node] = par, level[node] = lv;
ac[0][node] = par; // 첫번째(2^0) 조상은 부모
for (auto adj : adj_list[node]) {
if (adj == par) continue; // 부모방향 간선제거
tree[node].push_back(adj);
dfs(adj, node, lv + 1);
}
};
dfs(root, -INF, 1);
for (int i = 1; i <= max_level; i++) {
for (int j = 1; j < max_v; j++) {
int tmp = ac[i - 1][j];
if (tmp == -INF) continue;
ac[i][j] = ac[i - 1][tmp];
}
}
return { tree, root, parent, level,max_level, ac };
}
int lca(int u, int v, int max_level, vi& level, vvi& ancestor)
{
if (level[u] < level[v]) swap(u, v); // b가 더 깊도록 조정
int diff = level[u] - level[v];
for (int i = 0; diff; i++) {
if (diff & 1) u = ancestor[i][u]; //b를 올려서 level을 맞춘다.
diff >>= 1;
}
if (u == v) return u;
for (int i = max_level; i >= 0; i--) {
// a와 b가 다르다면 현재 깊이가 같으니, 깊이를 a,b동시에 계속 올려준다.
if (ancestor[i][u] != ancestor[i][v])
u = ancestor[i][u], v = ancestor[i][v];
}
return ancestor[0][u];
}
int32_t main()
{
ios::sync_with_stdio(false); cin.tie(0); cout.tie(0);
int N; cin >> N; vvi adj_list(N + 1);
for (int i = 0; i < N - 1; i++) {
int u, v; cin >> u >> v;
adj_list[u].push_back(v);
adj_list[v].push_back(u);
}
result r = treefy(adj_list, 1, true);
int m; cin >> m; for (int z = 0; z < m; z++)
{
int a, b; cin >> a >> b;
int ans = lca(a, b, r.max_level, r.level, r.ancestor);
cout << (ans) << '\n';
}
return 0;
}