
branch생성시점의 master가 너무 오래돼서, 최신 master의 branch로 업데이트 하고 싶을때
방법1. merge
방법2. rebase
타인이 올린 PR의 Files changed를 터미널에서 확인하기
현재 master의 최신이 아닌 PR을 올린사람이 작업을 시작할때의 master가 기준이 됨에 유의
git fetch origin
git diff $(git merge-base origin/master origin/pr-branch-name)..origin/pr-branch-name
타인이 올린 PR을 내 로컬로 가져와서 검토하기
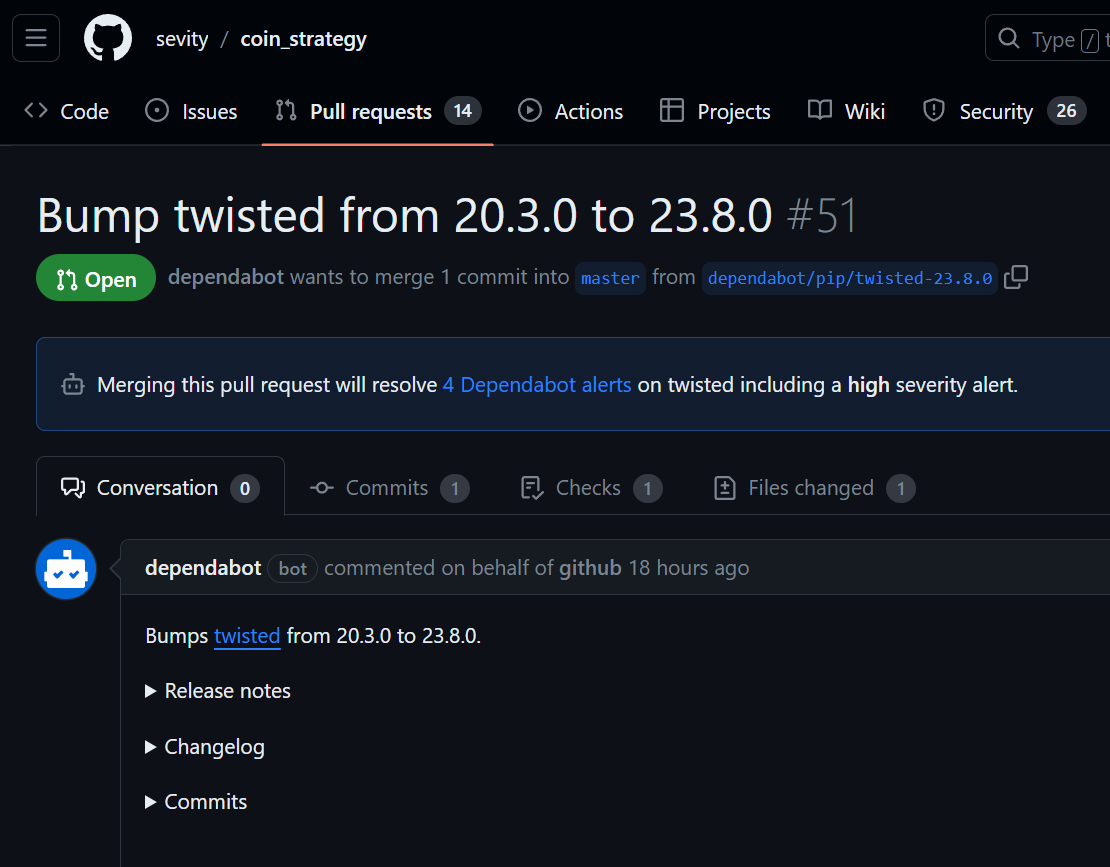
예를들어 위와 같은 PR이 올라왔다고 하자.
git fetch origin pull/51/head:bump-twisted 라고 치면 로컬에 "bump-twisted"라고 하는 브랜치가 생성된다(이것은 임의로 지정한 이름이며 생략하면 "pull/51/head"가 된다)
git branch를 해보면 아래처럼 bump-twisted라는 브랜치가 로컬 저장소에 추가된 것을 볼 수 있다.
$ git branch
* master
bump-twisted아직은 master를 바라보고 있어 PR의 내용이 로컬저장소에 반영되지 않았다.
git checkout bump-twisted 라고 치면 반영된다.
만약 PR을 올린사람이 merge전에 PR의 내용을 변경했다면
git pull origin pull/51/head:bump-twisted 다시 이렇게 치면 된다.
위 방법대신
git branch -r을 해보면 다음처럼 이미 해당 PR들의 branch 들이 생성되어 있는 것을 볼 수 있는데,
(coin) sevity@raspberrypi:~/workspace/temp/coin_strategy $ git branch -r
origin/HEAD -> origin/master
origin/dependabot/pip/tornado-6.3.3
origin/dependabot/pip/twisted-23.8.0
origin/dependabot/pip/urllib3-1.26.18
origin/master여기서 해당 PR을 확인하고 git pull origin dependabot/pip/twisted-23.8.0:bump-twisted 이렇게 하는 방법도 있다.
반응형
'Programming > Git' 카테고리의 다른 글
| git 초기설정 (0) | 2023.06.06 |
|---|---|
| git log (0) | 2019.12.09 |
| git 자주 쓰는 명령어 모음 (0) | 2019.09.27 |
| git branch 관련 (0) | 2019.04.17 |
| github (0) | 2018.11.07 |