
먼저 디시전트리를 보고 오자.
개요
랜덤 포레스트(Random Forest)는 앙상블 학습 방법의 일종으로, 여러 개의 결정 트리를 학습시키고 그들의 예측을 결합하여 작동. 이 방식은 개별 트리의 예측의 정확도를 향상시키며, 과적합을 방지할 수 있다.
단계1. 부트스트랩 샘플링 (Bootstrap Sampling):
랜덤 포레스트는 각 트리를 학습시키기 위해 부트스트랩 샘플을 생성.
(Bootstrap"은 통계학에서 무작위로 샘플을 복원 추출하는 방법을 의미)
배깅의 기본 아이디어
부트스트랩 샘플은 원본 데이터 세트에서 중복을 허용하여 무작위로 선택된 샘플로 구성되며, 데이터개수는 원본의 크기를 유지.
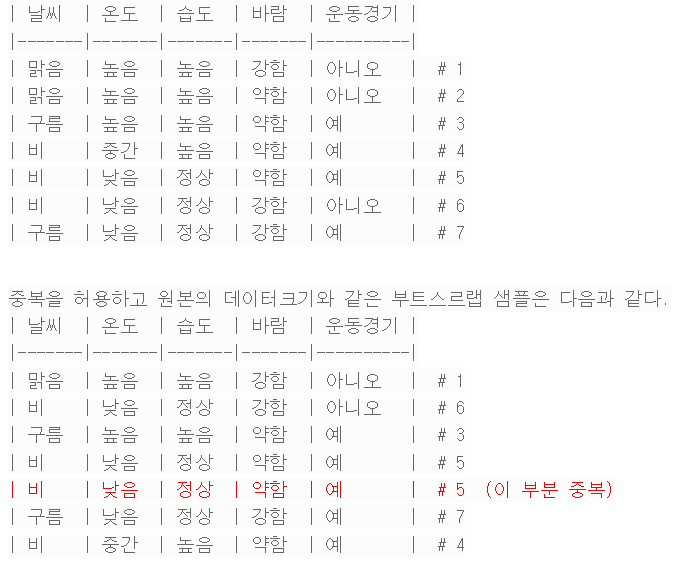
부트스트랩이란 용어에 대해서는 다음을 참고하자.
"Bootstrapping"이라는 용어는 오래된 서양 표현 "to pull oneself up by one's bootstraps"에서 비롯되었습니다. 이 표현은 불가능한 일을 수행하려는 노력을 의미하며, 원래는 물리적으로 자신의 부츠 끈(bootstraps)을 당겨서 자신을 공중에 띄우는 것이 불가능하다는 것을 나타내기 위해 사용되었습니다. 하지만 시간이 지나면서, 이 표현은 더 긍정적이고 상징적인 의미로 발전하게 되었습니다. 이제 "to pull oneself up by one's bootstraps"는 개인이 자신의 노력과 자원으로 어려운 상황을 극복하고 성공을 달성할 수 있음을 나타냅니다. 이는 무엇인가를 시작하거나 개선하기 위해 외부 도움 없이 자신의 능력과 자원을 사용하는 것을 의미합니다.웹 개발과 통계학에서 "Bootstrapping"의 사용은 이러한 개념을 반영합니다:
웹 개발의 부트스트랩:웹 개발 분야에서 부트스트랩은 개발자가 기본 구조와 디자인을 빠르게 설정하고, 프로젝트를 더 빠르게 시작하고 진행할 수 있도록 돕는 프레임워크입니다. 이는 개발자가 외부 디자인 팀이나 추가 자원 없이도 효과적인 웹사이트를 구축할 수 있게 해줍니다.
통계학의 부트스트랩 샘플링:통계학에서 부트스트랩 샘플링은 원본 데이터셋만을 사용하여 통계적 추정을 수행하는 방법을 제공합니다. 이는 외부 데이터 또는 추가 정보 없이도 원본 데이터셋의 특성을 이해하고 분석할 수 있게 해줍니다.
이런 방식으로, "Bootstrapping"은 독립성과 자립성의 중요성을 강조하며, 제한된 자원으로도 무언가를 성취할 수 있음을 상징합니다.
단계2. 특성 무작위 선택:
데이터만 무작위 샘플링하는게 아니라, 날씨/온도/습도등 각 노드에서 분할을 수행하는 특성도 일부 특성만을 무작위로 선택하여 사용. 이 방식은 트리의 다양성을 증가시키며, 과적합을 방지
단계3. 단계1,2를 통해 생성된 다수의 결정 트리를 개별 학습
랜덤 포레스트는 위의 두 과정을 통해 여러 개의 결정 트리를 독립적으로 학습.
각 트리는 약간 다른 부트스트랩 샘플과 약간 다른 특성 집합을 사용하여 학습됨.
단계4. 앙상블을 통한 집계:
분류 문제의 경우, 랜덤 포레스트는 각 트리의 예측을 모아서 투표를 통해 최종 클래스 레이블을 결정.
회귀 문제의 경우, 랜덤 포레스트는 각 트리의 예측을 평균내어 최종 예측을 생성.
단계5. 아웃 오브 백 (Out of Bag) 평가:
중복을 허용하는 부트스르랩 샘플링의 특성에 의해 피전홀 원칙에 따라 일부 샘플은 특정 개별 트리 학습과정에서 제외된다(위의 예시에서는 #2번 샘플)
이러한 샘플을 사용하여 트리의 성능을 평가하고, 랜덤 포레스트의 전반적인 성능을 추정할 수 있다.
학습에 사용되지 않은 아웃 오브 백 샘플을 사용하여 각 트리의 성능을 평가하고, 이는 각 트리에 대한 오류율을 측정하는 데 사용될 수 있다.
랜덤 포레스트 평가: 모든 트리의 아웃 오브 백 오류율을 평균하여 랜덤 포레스트의 전반적인 아웃 오브 백 오류율을 계산. 이는 랜덤 포레스트 모델의 전반적인 성능을 추정하는 데 사용될 수 있다.
단계6. 일반적인 평가
랜덤 포레스트의 평가에 있어서 아웃 오브 백(Out of Bag, OOB) 평가는 선택적인 방법.
이는 별도의 검증 데이터셋을 필요로 하지 않으므로 유용할 수 있지만, 이는 랜덤 포레스트의 성능을 평가하는 유일한 방법은 아님. 실제로는, 다음과 같은 다양한 평가 방법들이 널리 사용됨
분할 검증 (Holdout Validation):
데이터를 학습 세트와 검증 세트로 분할하고, 학습 세트로 모델을 학습시킨 후 검증 세트로 모델의 성능을 평가.
교차 검증 (Cross-Validation):
데이터를 여러 개의 폴드로 분할하고, 각 폴드를 검증 세트로 사용하여 모델의 성능을 평가.
- K번의 반복을 수행.
- 각 반복에서 하나의 폴드를 검증 세트로 선택하고, 나머지 K−1개의 폴드를 학습 세트로 사용
- 모델을 학습 세트로 학습시키고, 검증 세트로 모델의 성능을 평가.
이 방법은 모델의 성능을 보다 안정적으로 평가할 수 있음
부트스트랩 검증 (Bootstrap Validation):
여러 번의 부트스트랩 샘플을 생성하고, 각 샘플로 모델을 학습 및 검증하여 모델의 성능을 평가.
'AI, ML > ML' 카테고리의 다른 글
| 디시전트리기반 코드 실습 (0) | 2023.10.16 |
|---|---|
| 그레디언트 부스팅 (Gradient Boosting) (0) | 2023.10.15 |
| 윈도우 환경에서 ML환경 구축 (0) | 2022.03.09 |
| 케라스(Keras) (0) | 2020.04.13 |
| Bayesian Online Changepoint Detection 논문리딩 (0) | 2019.08.21 |