
sdf
2024. 4. 16. 17:25
TF-IDF
2024. 3. 12. 14:21
다만 TF-IDF실제 계산 수치가 따로 해보면 똑같이 잘 안나온다.
Q. TF-IDF계산하면 원본 문장에서 단어별로 TF-IDF스칼라 값이 하나 나온다?
A. 맞다.
반응형
'AI, ML > ML' 카테고리의 다른 글
| 문자열을 벡터로 바꾸는 방법2 - TfidfVectorizer (0) | 2024.03.12 |
|---|---|
| 문자열을 벡터로 바꾸는 방법1 - CountVectorizer (0) | 2024.03.12 |
| cardinality (1) | 2024.01.07 |
| dense feature vs sparse feature (0) | 2024.01.07 |
| binning (0) | 2023.12.28 |
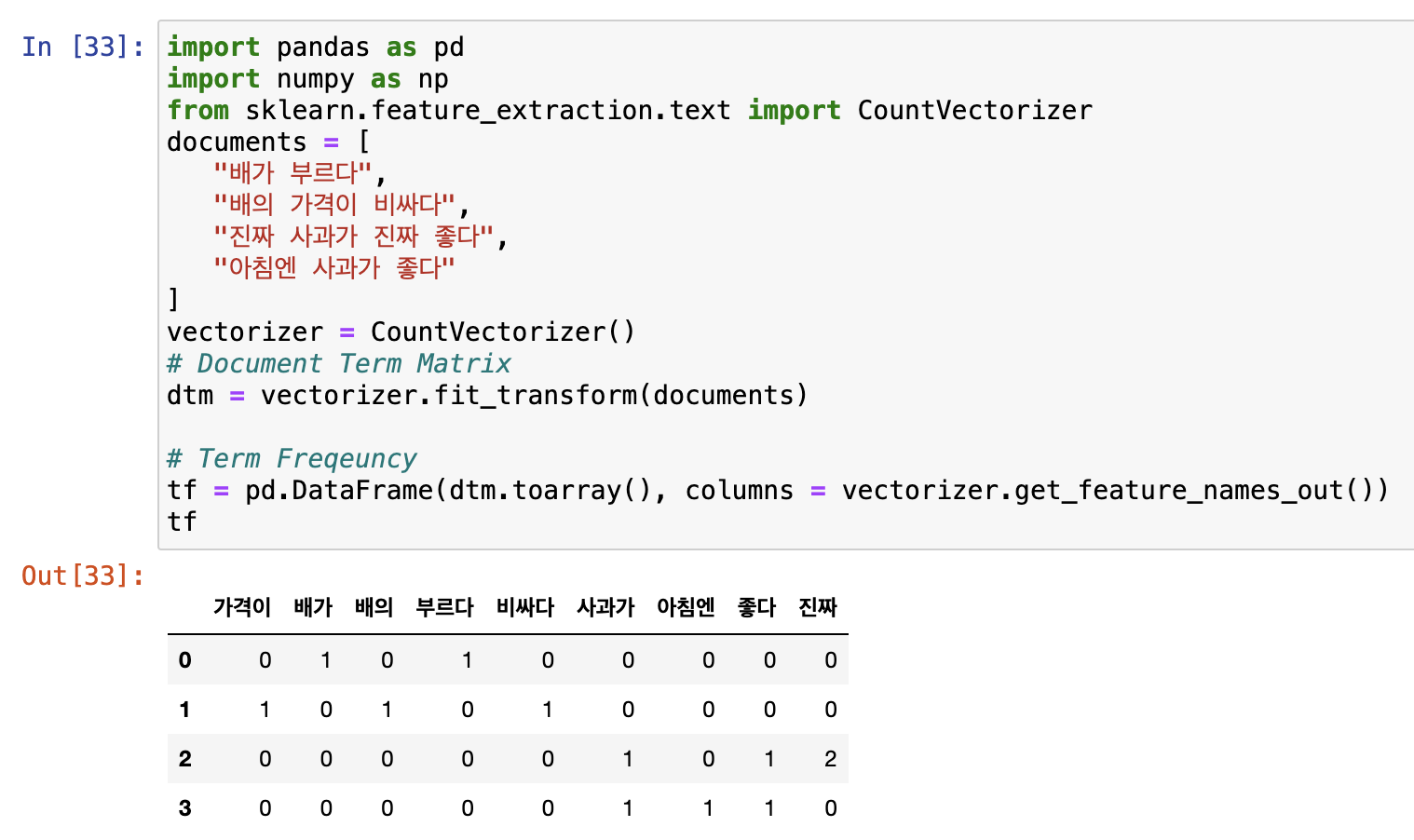
문자열을 벡터로 바꾸는 방법2 - TfidfVectorizer
2024. 3. 12. 13:54
TF-IDF는 여기 참조
예시코드
from sklearn.feature_extraction.text import TfidfVectorizer
text_data = ['사과 바나나 자동차', '바나나 자동차 기차',
'자동차 기차 사과 포도', '바다 사과 기차 여름']
tfidfvec = TfidfVectorizer()
tfidfvec.fit(text_data)
print("Vocabulary: ", tfidfvec.vocabulary_)
sentence = [text_data[0]]
print(sentence)
print(tfidfvec.transform(sentence).toarray())
결과
Vocabulary: {'사과': 3, '바나나': 1, '자동차': 5, '기차': 0, '포도': 6, '바다': 2, '여름': 4}
['사과 바나나 자동차']
[[0. 0.65782931 0. 0.53256952 0. 0.53256952
0. ]]보면 알겠지만 '사과 바나나 자동차' 입력 문장에서의 단어개수가 아닌 전체 단어개수(기차0부터 포도6까지 7개)에 해당하는 벡터가 생성된다.
직접 tf-idf값을 계산해보려면 아래 참조

반응형
'AI, ML > ML' 카테고리의 다른 글
| TF-IDF (0) | 2024.03.12 |
|---|---|
| 문자열을 벡터로 바꾸는 방법1 - CountVectorizer (0) | 2024.03.12 |
| cardinality (1) | 2024.01.07 |
| dense feature vs sparse feature (0) | 2024.01.07 |
| binning (0) | 2023.12.28 |