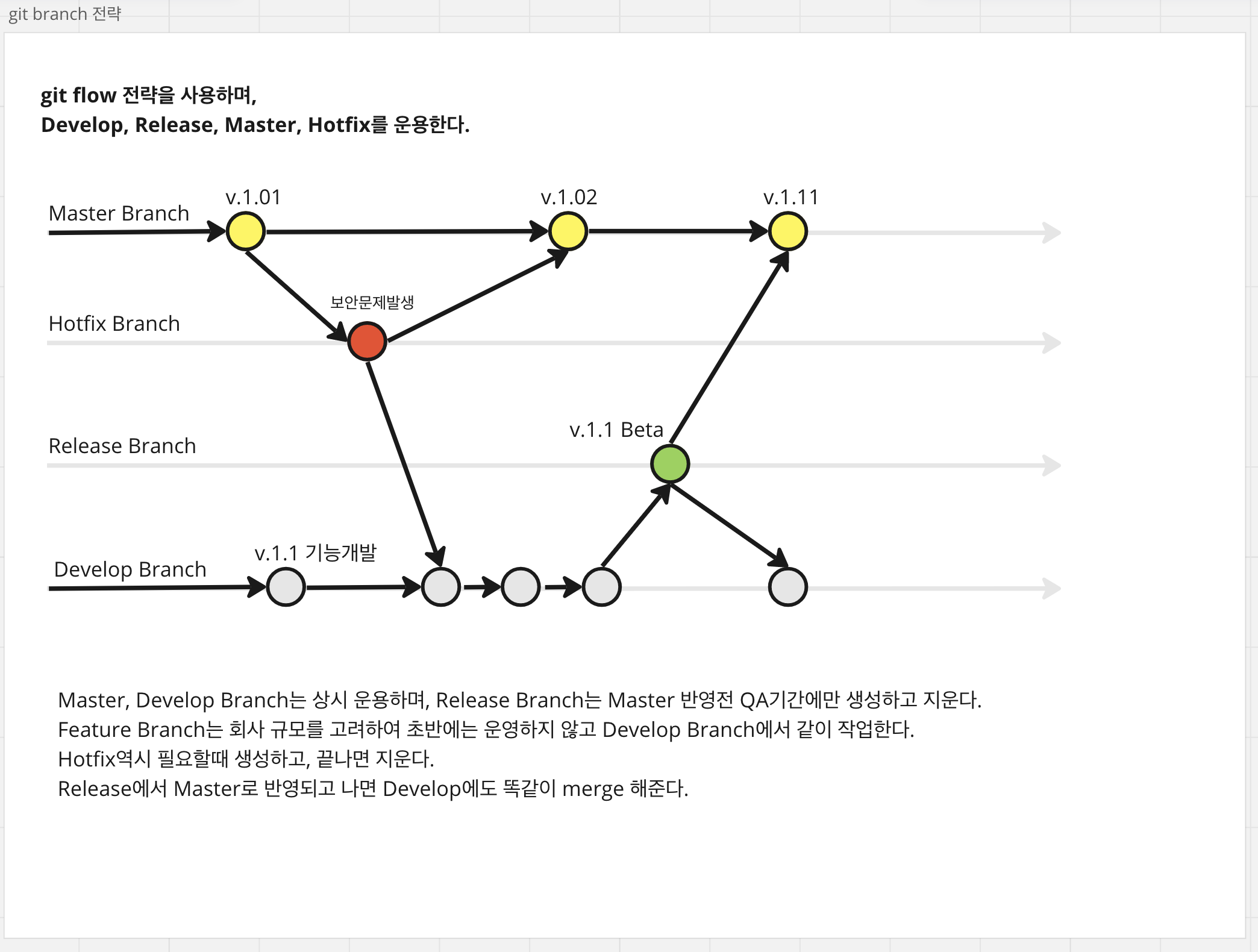
판정하고자 하는 n의 범위가 클 때는 아래 is_prime() 함수를 사용
bool is_prime(long long n)
{
if (n<2) return false;
for(long long it=2;it*it<=n;it++)
if(n%it==0) return false;
return true;
}
좀 더 빠른 함수를 원하면 아래 버전도 있다. 그러나 둘다 시간복잡도는 O(sqrt(N))으로 동일하다. 경험적으로는 3배정도 상수배로 아래 함수가 위 함수보다 빠르다.
bool is_prime(ll n)
{
// 코너케이스 검사
if (n <= 1)
return false;
if (n <= 3)
return true;
// 이 부분은 아래 루프에서 가운데 5개 숫자를 건너뛸 수 있도록 하는 검사입니다
if (n % 2 == 0 || n % 3 == 0)
return false;
// 소수의 개념을 사용합니다.
// 소수는 (6*n + 1) 또는 (6*n - 1)의 형태로 표현될 수 있으므로
// 6의 모든 배수에 대해 검사해야 하며,
// 소수는 항상 6의 배수보다 1 더 크거나 1 더 작습니다.
/*
1. 여기서 i는 5 + 6K의 형태이며, 여기서 K는 0 이상입니다.
2. i+1, i+3, i+5는 짝수 (6 + 6K)입니다. N은 짝수가 아닙니다.
3. N%2와 N%3 검사가 이전 단계에서 완료되었기 때문입니다.
4. 따라서 i+1, i+3, i+5는 N의 약수가 될 수 없습니다.
5. i+4는 9 + 6K 형태로, 3의 배수입니다.
6. N은 3의 배수가 아니므로, i+4는 N의 약수가 될 수 없습니다.
따라서 N이 i나 i+2의 약수인지만 확인합니다.
*/
for (ll i = 5; i * i <= n; i = i + 6)
if (n % i == 0 || n % (i + 2) == 0)
return false;
return true;
}
아래 밀러-라빈 소수판정법을 쓰면 n의 범위가 클 때, 위의 최적화된 코드 보다도 대략 20배정도 빠른 성능을 얻을 수 있고, 확률적 방법이긴 하지만, 실용적인 범위내에서는 다 맞는 결과를 도출한다. 시간복잡도는 O(k * log(n)^3)정도 된다.(k=3)
n<4,759,123,141일 경우 아래 코드는 정확히 동작하며 더 큰 범위에 대해서는 추가 처리가 필요하다(unsigned int를 long long등으로 바꿔주고 2,7,61 부분을 늘려줘야 한다, 참고로 unsigned int의 범위는 0부터 4,294,967,295까지로 위 범위안에 들어간다.)
bool is_prime(unsigned int n) {
if (n < 2) return 0;
if (n % 2 == 0) {
if (n == 2) return 1;
else return 0;
}
int s = __builtin_ctz(n - 1);
for (unsigned long long a: {2, 7, 61}) {
if (a >= n) continue;
int d = (n - 1) >> s;
unsigned long long now = 1;
while (d != 0) {
if (d & 1) now = (now * a) % n;
a = (a * a) % n;
d >>= 1;
}
if (now == 1) goto success;
for (int i = 0; i < s; ++i) {
if (now == n - 1) goto success;
now = (now * now) % n;
}
return 0;
success:;
}
return 1;
}
에라토스테네스의 채(sieve)
|
|
int np[10001]; // not prime
int main(void)
{
np[1]=1;
for(int i=2;i*i<10001;i++)
for(int j=2;i*j<10001;j++)
np[i*j]=1;
return 0;
}
|
cs |
stl버전
vector<bool> sieve(int max)
{
vector<bool> p(max+1, true);
p[0] = p[1]=false;
for(int i=2;i*i<=max;i++)
for(int j=2;i*j<=max;j++)
p[i*j]=false;
return p;
}
소인수 분해
|
|
int main(){
int t;cin >> t;
for(int i=2; i*i<=t; i++){
while(t%i == 0){
printf("%d\n",i);
t /= i;
}
}
if(t > 1) printf("%d",t); // 이 부분 주의
}
|
cs |
t%i 부분에서 소수가 아니어서 문제가 될 것 같지만, 합성수의 경우 소수로 먼저 나눠떨어진 이후에 접근되어 괜찮음
소수 배열 생성기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void gen_primes(vector<int>&primes, int max) {
// 아래 줄이 없으면 max가 1이하로 들어올때 빈 엘리먼트가 리턴돼서 문제되는 경우가 있음
// 물론 max가 1 이하일때 빈 엘리먼트가 리턴되는게 더 정확한 동작이긴 한데
// 라이브러리의 관용성 측면에서 하나라도 엘리먼트가 있는게 함수밖 예외처리가 간단해짐
primes.push_back(2);
for (int i = 3; i <= max; i++)
{
bool prime = true;
for (int j = 0; j < primes.size() && primes[j] * primes[j] <= i; j++)
{
if (i % primes[j] == 0)
{
prime = false;
break;
}
}
if (prime) primes.push_back(i);
}
}
|
cs |
소수로 이루어진 배열이 필요하면 위의 함수를 쓰면 된다. 예를 들어 이 문제의 답안에 쓰일 수 있다.
근데, 신기하게도, 아래처럼 먼저 체로 거르고 벡터에 담는게 두배정도 빠르다.
vector bool로 바꾸면서 또 두배 빨라짐
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void gen_primes(vector<int>&primes, int max) {
vector<bool> np(max + 1, false);
for (int i = 2; i <= max; i++) {
if (np[i]) continue;
for (int j = 2 * i; j <= max; j += i) {
np[j] = true;
}
}
primes.push_back(2);
for (int i = 3; i <= max; i++) {
if (!np[i]) primes.push_back(i);
}
}
|
cs |
아래처럼 바꾸니까, 또 위에서 3배 빨라졌다 (총 12배 ㄷ)
|
|
void gen_primes(vector<int>& primes, int max) {
vector<bool> np(max + 1, false);
for (int i = 3; i * i <= max; i += 2)
if (!np[i])
for (int j = i * i; j <= max; j += i + i)
np[j] = true;
primes.push_back(2);
for (int i = 3; i <= max; i += 2) if (!np[i]) primes.push_back(i);
}
|
cs |