from sklearn.datasets import load_wine
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb
import numpy as np
# 데이터 로딩
data = load_wine()
X, y = data.data, data.target
# 디시전 트리 모델 생성
dt = DecisionTreeClassifier()
# 랜덤 포레스트 모델 생성
rf = RandomForestClassifier()
# XGBoost 모델 생성
xg_cls = xgb.XGBClassifier()
# 교차 검증 수행 (5-fold CV)
cv_scores_dt = cross_val_score(dt, X, y, cv=5)
cv_scores_rf = cross_val_score(rf, X, y, cv=5)
cv_scores_xgb = cross_val_score(xg_cls, X, y, cv=5)
# 평균 정확도 출력
print(f'Decision Tree CV Accuracy: {np.mean(cv_scores_dt):.2f}')
print(f'Random Forest CV Accuracy: {np.mean(cv_scores_rf):.2f}')
print(f'XGBoost CV Accuracy: {np.mean(cv_scores_xgb):.2f}')
출력
$ python wine_test.py
Decision Tree CV Accuracy: 0.87
Random Forest CV Accuracy: 0.97
XGBoost CV Accuracy: 0.95
랜덤 포레스트(Random Forest)는 앙상블 학습 방법의 일종으로, 여러 개의 결정 트리를 학습시키고 그들의 예측을 결합하여 작동. 이 방식은 개별 트리의 예측의 정확도를 향상시키며, 과적합을 방지할 수 있다.
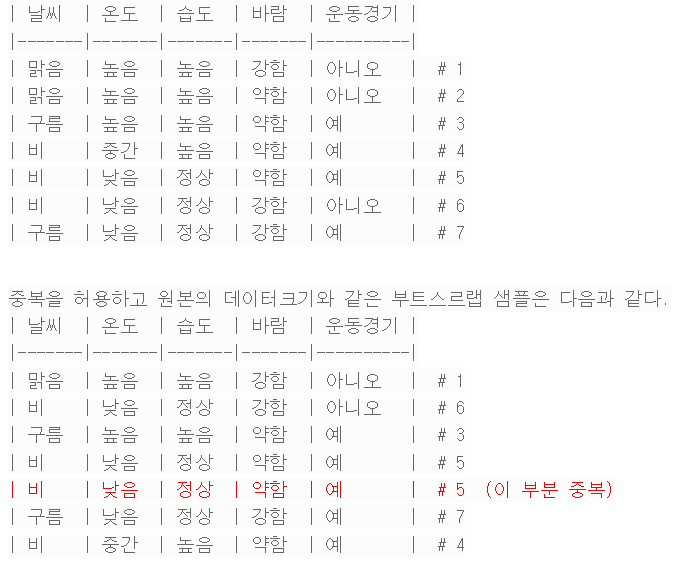
단계1. 부트스트랩 샘플링 (Bootstrap Sampling):
랜덤 포레스트는 각 트리를 학습시키기 위해 부트스트랩 샘플을 생성.
(Bootstrap"은 통계학에서 무작위로 샘플을 복원 추출하는 방법을 의미)
배깅의 기본 아이디어
부트스트랩 샘플은 원본 데이터 세트에서 중복을 허용하여 무작위로 선택된 샘플로 구성되며, 데이터개수는 원본의 크기를 유지.
부트스트랩이란 용어에 대해서는 다음을 참고하자.
"Bootstrapping"이라는 용어는 오래된 서양 표현 "to pull oneself up by one's bootstraps"에서 비롯되었습니다. 이 표현은 불가능한 일을 수행하려는 노력을 의미하며, 원래는 물리적으로 자신의 부츠 끈(bootstraps)을 당겨서 자신을 공중에 띄우는 것이 불가능하다는 것을 나타내기 위해 사용되었습니다. 하지만 시간이 지나면서, 이 표현은 더 긍정적이고 상징적인 의미로 발전하게 되었습니다. 이제 "to pull oneself up by one's bootstraps"는 개인이 자신의 노력과 자원으로 어려운 상황을 극복하고 성공을 달성할 수 있음을 나타냅니다. 이는 무엇인가를 시작하거나 개선하기 위해 외부 도움 없이 자신의 능력과 자원을 사용하는 것을 의미합니다.웹 개발과 통계학에서 "Bootstrapping"의 사용은 이러한 개념을 반영합니다:
웹 개발의 부트스트랩:웹 개발 분야에서 부트스트랩은 개발자가 기본 구조와 디자인을 빠르게 설정하고, 프로젝트를 더 빠르게 시작하고 진행할 수 있도록 돕는 프레임워크입니다. 이는 개발자가 외부 디자인 팀이나 추가 자원 없이도 효과적인 웹사이트를 구축할 수 있게 해줍니다.
통계학의 부트스트랩 샘플링:통계학에서 부트스트랩 샘플링은 원본 데이터셋만을 사용하여 통계적 추정을 수행하는 방법을 제공합니다. 이는 외부 데이터 또는 추가 정보 없이도 원본 데이터셋의 특성을 이해하고 분석할 수 있게 해줍니다.
이런 방식으로, "Bootstrapping"은 독립성과 자립성의 중요성을 강조하며, 제한된 자원으로도 무언가를 성취할 수 있음을 상징합니다.
단계2. 특성 무작위 선택:
데이터만 무작위 샘플링하는게 아니라, 날씨/온도/습도등 각 노드에서 분할을 수행하는 특성도 일부 특성만을 무작위로 선택하여 사용. 이 방식은 트리의 다양성을 증가시키며, 과적합을 방지
단계3. 단계1,2를 통해 생성된 다수의 결정 트리를 개별 학습
랜덤 포레스트는 위의 두 과정을 통해 여러 개의 결정 트리를 독립적으로 학습.
각 트리는 약간 다른 부트스트랩 샘플과 약간 다른 특성 집합을 사용하여 학습됨.
단계4. 앙상블을 통한 집계:
분류 문제의 경우, 랜덤 포레스트는 각 트리의 예측을 모아서 투표를 통해 최종 클래스 레이블을 결정. 회귀 문제의 경우, 랜덤 포레스트는 각 트리의 예측을 평균내어 최종 예측을 생성.
단계5. 아웃 오브 백 (Out of Bag) 평가:
중복을 허용하는 부트스르랩 샘플링의 특성에 의해 피전홀 원칙에 따라 일부 샘플은 특정 개별 트리 학습과정에서 제외된다(위의 예시에서는 #2번 샘플) 이러한 샘플을 사용하여 트리의 성능을 평가하고, 랜덤 포레스트의 전반적인 성능을 추정할 수 있다.
학습에 사용되지 않은 아웃 오브 백 샘플을 사용하여 각 트리의 성능을 평가하고, 이는 각 트리에 대한 오류율을 측정하는 데 사용될 수 있다. 랜덤 포레스트 평가: 모든 트리의 아웃 오브 백 오류율을 평균하여 랜덤 포레스트의 전반적인 아웃 오브 백 오류율을 계산. 이는 랜덤 포레스트 모델의 전반적인 성능을 추정하는 데 사용될 수 있다.
단계6. 일반적인 평가
랜덤 포레스트의 평가에 있어서 아웃 오브 백(Out of Bag, OOB) 평가는 선택적인 방법. 이는 별도의 검증 데이터셋을 필요로 하지 않으므로 유용할 수 있지만, 이는 랜덤 포레스트의 성능을 평가하는 유일한 방법은 아님. 실제로는, 다음과 같은 다양한 평가 방법들이 널리 사용됨
분할 검증 (Holdout Validation): 데이터를 학습 세트와 검증 세트로 분할하고, 학습 세트로 모델을 학습시킨 후 검증 세트로 모델의 성능을 평가.
교차 검증 (Cross-Validation): 데이터를 여러 개의 폴드로 분할하고, 각 폴드를 검증 세트로 사용하여 모델의 성능을 평가.
K번의 반복을 수행.
각 반복에서 하나의 폴드를 검증 세트로 선택하고, 나머지 K−1개의 폴드를 학습 세트로 사용
모델을 학습 세트로 학습시키고, 검증 세트로 모델의 성능을 평가.
이 방법은 모델의 성능을 보다 안정적으로 평가할 수 있음
부트스트랩 검증 (Bootstrap Validation): 여러 번의 부트스트랩 샘플을 생성하고, 각 샘플로 모델을 학습 및 검증하여 모델의 성능을 평가.
후자가 Resolver(리졸버)만 구현하면 스키마를 자동생성해주고 kotlin 타입과 연동되는등 kotlin을 사용한다면 더 편리한 측면이 있지만, 여기서는 전자를 사용한 기준으로 서술한다.
expediagroup 아티펙트의 경우, 내 경우엔 /graphql 404문제가 해결이 안돼서 springframework를 쓰기로 했다. 추가로 조사해보니 webmvc대신 webflux로 교체해야 호환되는 이슈도 있었다(여기) spring-boot-starter-web 대신 spring-boot-starter-webflux의존성으로 바꿔야 하는데 WebConfig.kt등 여러곳에서 코딩방식을 바꿔야 하는 걸로 보인다.
클라이언트 사이드(React/Next.js)
관련 library설치
npm install @apollo/client graphql
아폴로?
Apollo Client는 JavaScript 어플리케이션에서 GraphQL API와 통신할 수 있게 해주는 라이브러리입니다.
Facebook에서는 GraphQL을 발명했으며, Relay라는 GraphQL 클라이언트를 만들어 공개했습니다. 그러나 Apollo가 Relay보다 더 널리 사용되는 이유는 사용자 친화적: Apollo는 사용자 친화적이고, 초보자에게 친숙하며, 설정이 상대적으로 간단합니다. 문서화도 잘 되어 있어, 개발자들이 쉽게 접근하고 사용할 수 있습니다. 커뮤니티 지원: Apollo는 강력한 커뮤니티 지원을 받고 있으며, 다양한 추가 기능과 툴이 개발되고 있습니다. 또한 꾸준한 업데이트와 개선이 이루어지고 있어, 더 많은 개발자들이 Apollo를 선호하게 되었습니다.
src/main/resources/graphql/schema.graphqls 파일에 쿼리를 추가
type Query {
submissionCountByProblem(problemId: ID!): Int
}
2. 서비스 수정
SubmissionService에 getSubmissionCountByProblem매서드를 추가하여 문제별 제출 수를 가져옴
@Service
class SubmissionService(private val submissionRepository: SubmissionRepository) {
// 아래는 기존에 존재하던 매서드
fun submitProblem(userId: Long, problemId: Int, code: String): Submission {
val submission = Submission(
userId = userId,
problemId = problemId,
code = code,
status = "PENDING" // 초기 상태
)
return submissionRepository.save(submission)
}
// 아래 매서드 추가
fun getSubmissionCountByProblem(problemId: Int): Int {
return submissionRepository.countByProblemId(problemId)
}
}
3. 컨트롤러에 로직 추가
컨트롤러에@QueryMapping 어노테이션을 사용하여 submissionCountByProblem GraphQL쿼리를 처리하는 메서드를 추가(엔드포인트 추가는 아니지만 약간 유사)
package com.sevity.problemservice.controller
import ...
@RestController
class SubmissionController(private val submissionService: SubmissionService) {
// 기존 코드
// ...
@QueryMapping
fun submissionCountByProblem(@Argument problemId: Int): Int {
return submissionService.getSubmissionCountByProblem(problemId)
}
}
expediagroup 아티펙트의 경우, 위의 해결책을 적용해도 여전히 404가 떴고, 추가로 조사해보니 webmvc대신 webflux로 교체해야 하는 이슈가 있었다(여기) spring-boot-starter-web 대신 spring-boot-starter-webflux의존성으로 바꿔야 하는데 WebConfig.kt등 여러곳에서 코딩방식을 바꿔야 하는 걸로 보인다.
GraphQL은 서버 개발자에게 데이터 타입, 쿼리, 뮤테이션을 명시적으로 정의하도록 요구합니다. 이는 GraphQL 스키마에서 수행되며, 서버가 제공할 수 있는 데이터와 작업을 명확하게 정의합니다. 예를 들어, 서버 개발자는 사용자 데이터를 반환하는 getUser 쿼리와 사용자 데이터를 업데이트하는 updateUser 뮤테이션을 스키마에 정의할 수 있습니다.
클라이언트의 자유도 (Client Flexibility):
클라이언트는 서버에 정의된 스키마를 기반으로 데이터를 요청합니다.
필드 선택 (Field Selection):
클라이언트는 쿼리를 통해 필요한 필드만 선택할 수 있습니다. 예를 들어, 사용자 객체에 대한 쿼리를 만들 때, 클라이언트는 이름과 이메일만 요청할 수 있으며, 다른 필드는 무시할 수 있습니다. 이는 네트워크 트래픽을 최적화하고, 필요한 데이터만 가져오도록 할 수 있습니다.
중첩 및 복잡한 쿼리 (Nested and Complex Queries):
또한, 클라이언트는 중첩된 쿼리를 생성하여 관련된 객체와 필드를 한 번의 요청으로 가져올 수 있습니다. 이는 데이터의 관계와 구조를 유연하게 표현할 수 있으며, 복잡한 데이터 요청을 단순화할 수 있습니다.
응답 구조의 맞춤화 (Customized Response Structure):
클라이언트는 요청의 구조를 지정할 수 있으며, 서버는 클라이언트의 요청에 따라 응답을 제공합니다. 이는 클라이언트가 받고 싶은 데이터의 구조를 정확하게 지정할 수 있게 해줍니다.
type Query {
bookById(id: ID): Book
}
type Book {
id: ID
name: String
pageCount: Int
author: Author
}
type Author {
id: ID
firstName: String
lastName: String
}
장단점
Q&A
아니 무슨 단일 endpoint라고 자랑하더니 mutation마다 명세서를 만들어야 하는거 같네.(암튼 클라이언트 맘대로 쿼리하는 방임형 자유는 아닌거 같네) 이럴거면 endpoint 여러개인거랑 뭐가 다르지? Query의 경우는 개별 명세서가 필요 없나?
application.properties에서 포트설정해주고(이때 src/main/resources뿐 아니라 src/test/resources에 있는 파일도 해줘야함에 주의)
# in application.properties
grpc.server.port = 50051
다음처럼 gRPC서버 띄욱 listen작업도 해줘야 했다.
package com.sevity.authservice.config;
import ...
@Configuration
public class GrpcServerConfig {
private static final Logger logger = LoggerFactory.getLogger(GrpcServerConfig.class);
@Autowired
private SessionServiceImpl sessionService;
private Server server;
@Value("${grpc.server.port}")
private int port;
@PostConstruct
public void startServer() throws IOException {
server = ServerBuilder
.forPort(port)
.addService(sessionService) // Your gRPC service implementation
.build();
server.start();
logger.info("sevity gRPC server started on port {}", port);
logger.info("sevity gRPC service name: {}", sessionService.getClass().getSimpleName());
}
@PreDestroy
public void stopServer() {
if (server != null) {
server.shutdown();
}
logger.info("sevity gRPC server stopped");
}
}
gRPC는 Google이 개발한 고성능, 오픈 소스 및 범용의 원격 프로시저 호출(RPC) 프레임워크입니다.
효율적인 프로토콜로, 서버 간 통신에 아주 적합하며, Protocol Buffers를 사용하여 타입을 정의하고, 강력한 타입 검사와 높은 성능을 제공합니다. 이는 서로 다른 시스템 간에 통신을 가능하게 하며, 다양한 환경과 언어에서 작동합니다.
gRPC는 2015년 3월에 Google이 Stubby의 다음 버전을 개발하고 오픈 소스로 만들기로 결정했을 때 처음 생성되었습니다. gRPC의 최초 릴리스는 2016년 8월에 이루어졌습니다. 현재 gRPC의 최신 버전은 1.59.1(2023년 10월 6일기준)
장점:
기존의 REST등 텍스트 기반 프로토콜보다 더 효율적인 바이너리 프로토콜을 제공하여, 데이터 전송의 오버헤드를 줄이고 성능을 향상시킵니다.
컨트랙트 첫 접근 방식: 서비스의 인터페이스와 메시지를 먼저 정의하고, 이를 기반으로 코드를 생성합니다. (Protocol Buffers를 사용하여 데이터를 직렬화하고 역직렬화하여, 높은 성능을 제공합니다.)
스트리밍 및 빠른 통신: 양방향 스트리밍과 빠른 통신을 지원하여, 실시간 애플리케이션에 이상적입니다.
비동기 콜도 지원하는 것 같다.
단점:
복잡성: gRPC는 설정과 디버깅이 복잡할 수 있으며, 새로운 사용자에게 진입 장벽을 제공할 수 있습니다.
텍스트 기반 포맷의 부족: gRPC는 바이너리 프로토콜을 사용하므로, 텍스트 기반 프로토콜보다 디버깅이 어려울 수 있습니다.
브라우저 지원: gRPC-Web을 통해 브라우저에서 gRPC를 사용할 수 있지만, 네이티브 gRPC 클라이언트보다 기능이 제한적일 수 있습니다.
vs REST
REST는 HTTP/1.1을 기반으로 하며, 텍스트 기반의 JSON 또는 XML을 사용하여 데이터를 전송합니다. 이에 비해 gRPC는 HTTP/2를 기반으로 하며, 바이너리 기반의 Protocol Buffers를 사용합니다. gRPC는 REST보다 더 높은 성능과 더 낮은 데이터 오버헤드를 제공하지만, REST는 더 단순하고 더 넓게 지원됩니다.