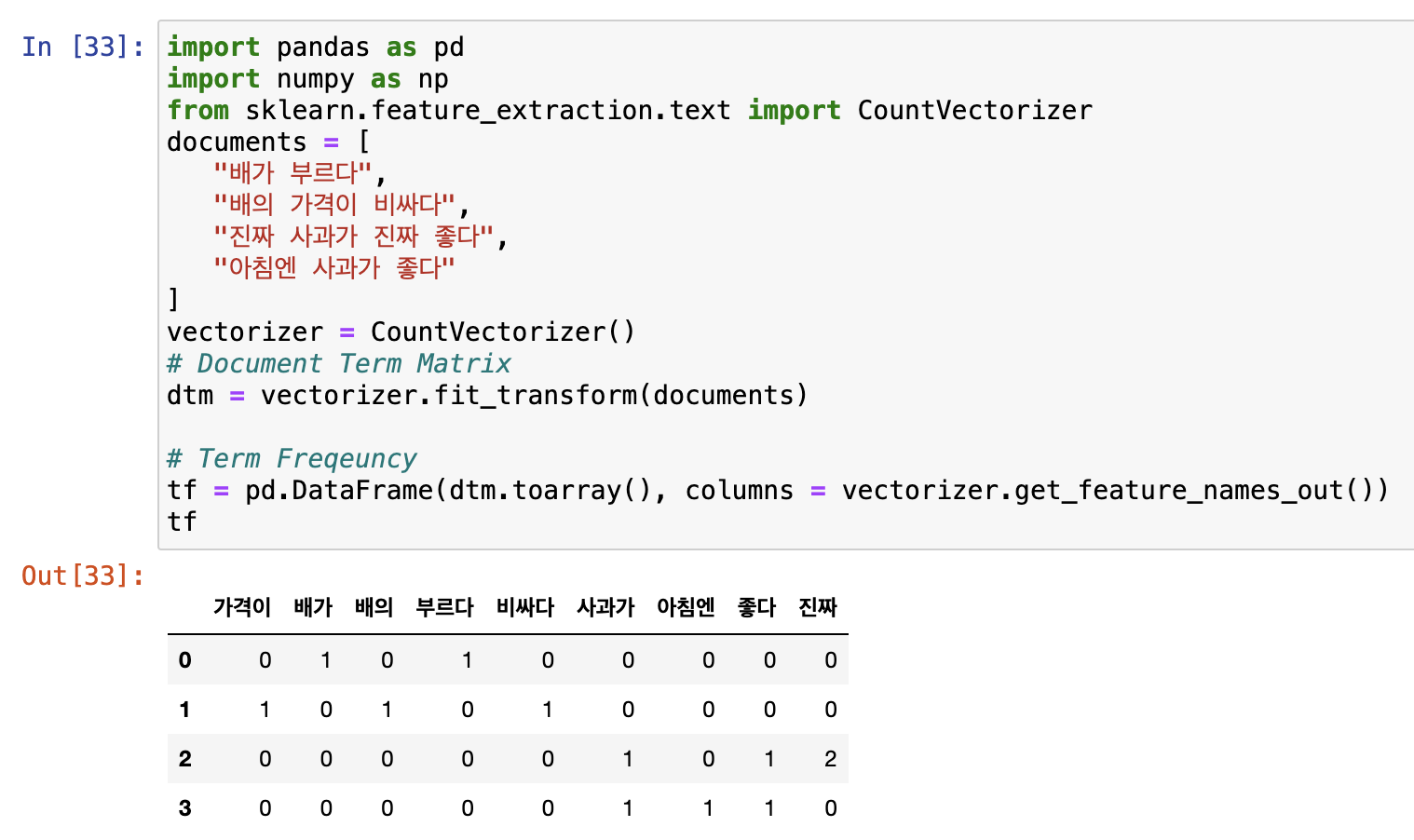
여기참조
from sklearn.feature_extraction.text import CountVectorizer
documents = [
'Hello, how are you? hello',
'I am fine, thank you.'
]
# CountVectorizer 인스턴스 생성
vectorizer = CountVectorizer()
# 문서를 피팅하고 변환
X = vectorizer.fit_transform(documents)
# 결과를 배열로 변환
X_array = X.toarray()
# 어휘 출력
print("Vocabulary: ", vectorizer.vocabulary_)
# 문서-단어 행렬 출력
print("Document-Term Matrix:\n", X_array)
결과
Vocabulary: {'hello': 3, 'how': 4, 'are': 1, 'you': 6, 'am': 0, 'fine': 2, 'thank': 5}
Document-Term Matrix:
[[0 1 0 2 1 0 1]
[1 0 1 0 0 1 1]]
Vocabulary는 단어별로 인덱스를 생성해주는 과정이고,
Document-Term Matrix를 통해 문자열을 벡터화 해준다.
벡터화 방법은 인덱스 위치별 등장횟수를 카운팅하는 단순한 방법이다.
특징
* 단어를 벡터로 표현한게 아니라. 문장(또는 문서) 전체가 하나의 벡터로 표현된다.
CountVector를 통한 스펨메일분류기 만들기
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 샘플 데이터: 이메일 텍스트와 스팸 여부
emails = ["Free money now!!!", "Hi Bob, how about a game of golf tomorrow?", "Exclusive offer, limited time only"]
labels = [1, 0, 1] # 1: 스팸, 0: 비스팸
# CountVectorizer로 텍스트 벡터화
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(emails)
# 결과를 배열로 변환
X_array = X.toarray()
# 어휘 출력
print("Vocabulary: ", vectorizer.vocabulary_)
# 문서-단어 행렬 출력
print("Document-Term Matrix:\n", X_array)
y = labels
# 데이터를 훈련 세트와 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# 로지스틱 회귀 모델 훈련
model = LogisticRegression()
model.fit(X_train, y_train)
# 스팸 탐지 테스트
print(model.score(X_test, y_test))
결과
Vocabulary: {'free': 3, 'money': 9, 'now': 10, 'hi': 6, 'bob': 1, 'how': 7, 'about': 0, 'game': 4, 'of': 11, 'golf': 5, 'tomorrow': 15, 'exclusive': 2, 'offer': 12, 'limited': 8, 'time': 14, 'only': 13}
Document-Term Matrix:
[[0 0 0 1 0 0 0 0 0 1 1 0 0 0 0 0]
[1 1 0 0 1 1 1 1 0 0 0 1 0 0 0 1]
[0 0 1 0 0 0 0 0 1 0 0 0 1 1 1 0]]
1.0
문장에서 벡터로 변환하는 방법이 단순하여 실용성은 적다.
하지만 자주 등장하는 단어가 주요하게 쓰이는 경우도 있고, 특징 추출의 기본이기 때문에 알아두어야한다.